Page Not Found
Page not found. Your pixels are in another canvas.

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Page not found. Your pixels are in another canvas.
About me
This is a page not in th emain menu
Short description of portfolio item number 1
Short description of portfolio item number 2 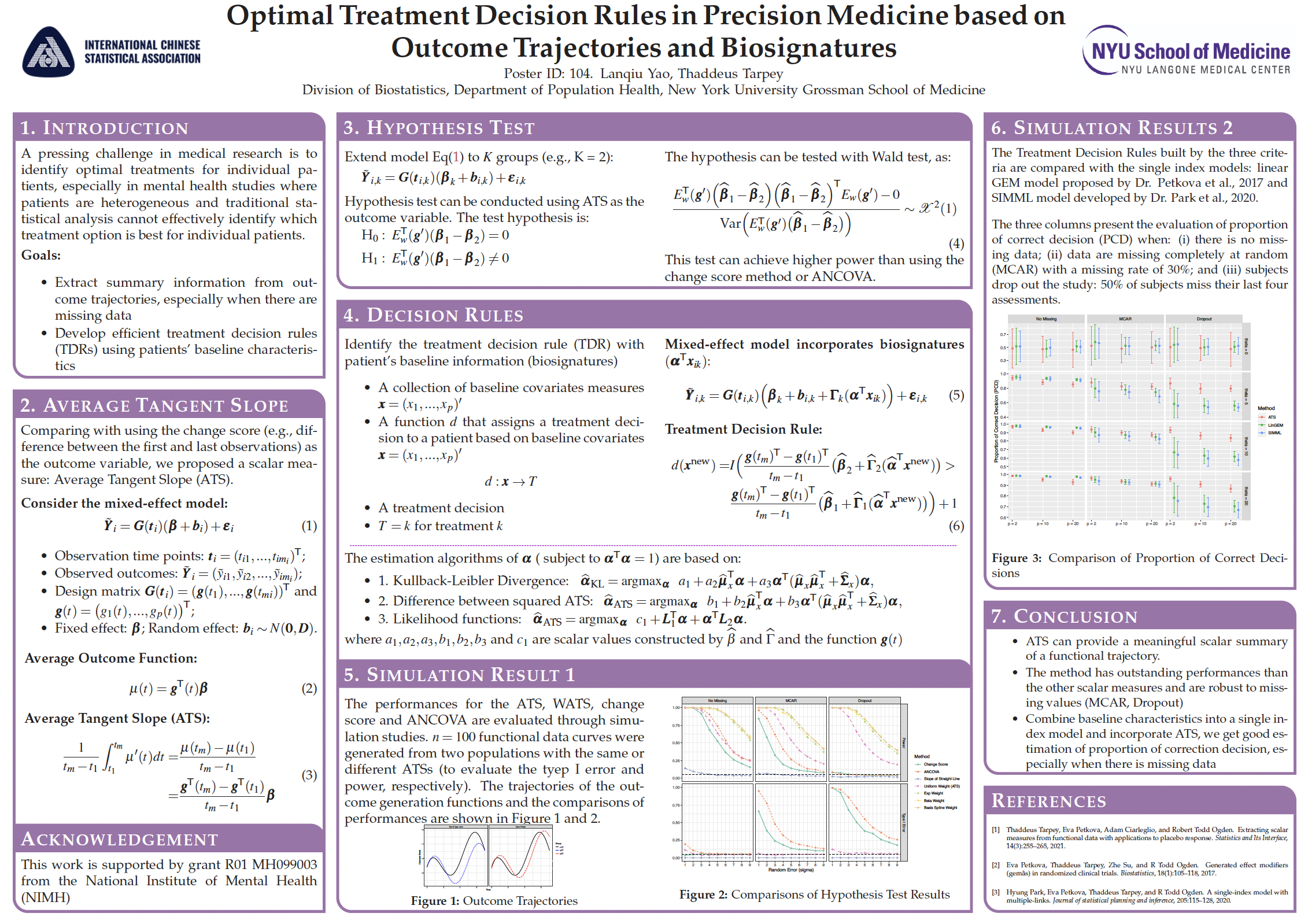
Published in Statistical Methods in Medical Research, 2009
This paper is about handling missing data in cluster randomize trials
Recommended citation: Turner, Elizabeth L., et al. "Properties and pitfalls of weighting as an alternative to multilevel multiple imputation in cluster randomized trials with missing binary outcomes under covariate-dependent missingness." Statistical methods in medical research 29.5 (2020): 1338-1353 https://github.com/sakuramomo1005/sakuramomo1005.github.io/blob/master/files/paper1.pdf
Published in Journal of Bioscience and Bioengineering, 2017
This paper is about engineered Escherichia coli cells to bind to cyanobacteria by heterologously producing and displaying lectins of the target cyanobacteria on their surface
Recommended citation: Zhang, Zijian, et al. "Engineering Escherichia coli to bind to cyanobacteria." Journal of bioscience and bioengineering 123.3 (2017): 347-352. https://github.com/sakuramomo1005/sakuramomo1005.github.io/blob/master/files/paper2.pdf
Published in Under review, 2021
This paper is about a bi-clustering algorithm
Recommended citation: Wang, Binhuan, et al. "A New Algorithm for Convex Biclustering and Its Extension to the Compositional Data." arXiv preprint arXiv:2011.12182 (2020). https://github.com/sakuramomo1005/sakuramomo1005.github.io/blob/master/files/paper3.pdf
Published:
Abstract: It is a continuing challenge in mental health research to identify patients who respond to treatment, since the treated and untreated patients often have similar outcomes on average. Precision medicine approaches, that consider an individual’s personal information, often produce treatment decision rules that are quite complicated. In this talk, I provide an approach to precision medicine to estimate a linear combination of patient baseline characteristics, i.e., a “biosignature”, defined to maximize the Kullback-Leibler Divergence between a treatment and control distribution. I will describe an algorithm to estimate the biosignature and illustrate the approach via a simulation study and a depression clinical trial.
Published:
A pressing challenge in medical research is to identify optimal treatments for individual patients. This is particularly challenging in mental health settings where mean responses are often similar across multiple treatments. This talk investigates a potentially powerful precision medicine approach to this problem by examining the impact of baseline covariates on longitudinal outcome trajectories instead of scalar outcome measures. For example, on average, patients treated with an active drug versus placebo may have similar trajectories, but specific trajectory shapes may be unique to individuals treated with the active medication. We introduce a method of estimating “biosignatures” defined as linear combinations of baseline characteristics (i.e., a single index) that optimally separate longitudinal trajectories among different treatment groups. The criterion used is to maximize the Kullback-Leibler Divergences between different treatment outcome distributions. The approach is illustrated via simulation studies and a depression clinical trial. The comparison of the method with other approaches is also presented.
Published:
It is increasingly common in practice to observe functional data(including longitudinal data) consisting of curves. It is oftennecessary to extract a scalar summary from functional data. Forexample, a scalar summary may be needed to compare treatments with nonlinear longitudinal outcomes. In precisionmedicine, scalar summaries of functional data are useful fordefining optimal treatment decision rules. In practice, scalarsummaries of functional data that are commonly used areinefficient because they ignore the functional information orlead to biased results (e.g., change scores or the slope of afitted line). These inefficiencies are usually compounded in thepresence of missing data. In this talk, we introduce a scalarmeasure from a functional observation based on a weightedaverage tangent slope (WATS). Since the tangent sloperepresents an instantaneous rate of improvement ordeterioration, an appropriately weighted average tangentslope can produce a useful summary from a functionalobservation that incorporates the shape of the trajectory. Inthis talk, we illustrate the WATS and demonstrate thatestimators of the WATS provide superior summaries offunctional data.
Published:
It is increasingly common in practice to observe functional data(including longitudinal data) consisting of curves. It is oftennecessary to extract a scalar summary from functional data. Forexample, a scalar summary may be needed to compare treatments with nonlinear longitudinal outcomes. In precisionmedicine, scalar summaries of functional data are useful fordefining optimal treatment decision rules. In practice, scalarsummaries of functional data that are commonly used areinefficient because they ignore the functional information orlead to biased results (e.g., change scores or the slope of afitted line). These inefficiencies are usually compounded in thepresence of missing data. In this talk, we introduce a scalarmeasure from a functional observation based on a weightedaverage tangent slope (WATS). Since the tangent sloperepresents an instantaneous rate of improvement ordeterioration, an appropriately weighted average tangentslope can produce a useful summary from a functionalobservation that incorporates the shape of the trajectory. Inthis talk, we illustrate the WATS and demonstrate thatestimators of the WATS provide superior summaries offunctional data.
PhD course, NYU, School of Medicine, 2020
PhD course, NYU School of Medicine, 2020